


在人工智能领域,语言模型(LM)的发展令人瞩目。近年来,庞大的训练数据集推动了这一领域的进步。然而,数据集的质量和训练成本也成了研究人员关注的焦点。本文将介绍一个全新的测试平台——DataComp-LM,它旨在探索和优化语言模型的训练数据集。
语言模型越来越多地用于解决各种任务的通用问题,但是它们在推理过程中仍然被限制在基于标记的、从左到右的决策过程中。这意味着在需要探索、战略前瞻或初始决策至关重要的任务中,它们可能会表现不佳。
大型预训练语言模型(LLM)已经被证明在各个领域的少样本学习中具有重要潜力,即使只有很少的训练数据。然而,它们在更复杂的领域(如生物学)中泛化到未见过的任务的能力尚未完全评估。LLM可以通过从文本语料库中提取先前的知识,在结构化数据和样本量有限的情况下,为生物推理提供有希望的替代方法。
基于Transformer的大语言模型在机器学习研究领域中快速发展,应用范围涵盖自然语言、生物学、化学和计算机编程等领域。极端的扩展和通过人类反馈的强化学习显著提高了生成文本的质量,使得这些模型能够执行各种任务并推理选择。
随着最近的技术突破,研究人员开始对可用的大量生物医学数据采用多种机器学习技术。在生物医学文献中使用文本挖掘和知识提取等技术已被证明对于开发新药物、临床治疗、病理学研究等至关重要。由于不断的科学进步,每天都会出版越来越多的生物医学出版物,因此需要不断地从这些材料中提取有意义的信息。这就是预训练语言模型发挥作用的地方。由于预训练语言模型在一般自然语言领域的卓越有效性,生物医学研究人员对其产生了浓厚兴趣。
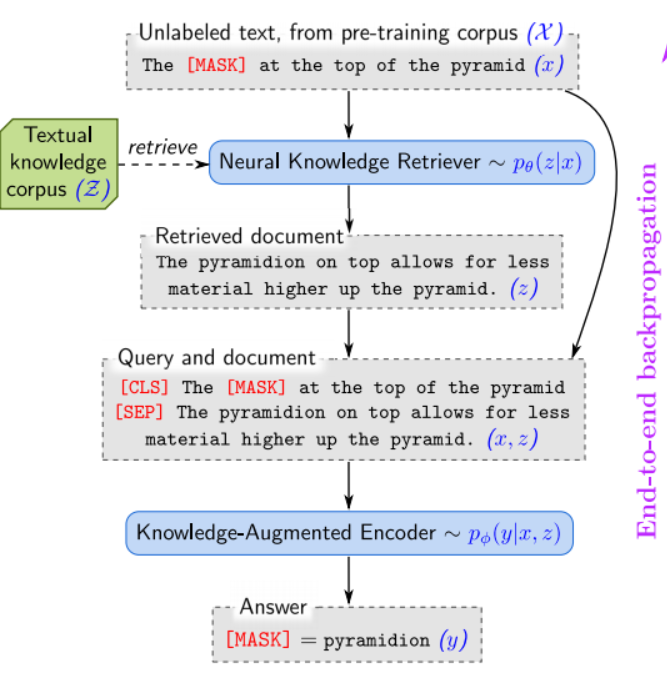
谷歌已经发布了一种预训练语言模型的新方法,Google的REALM是一种基于知识库的增强语言模型。该方法使用知识检索机制进行增强语言模型,该机制可以从外部Wikipedia语料库中查找现有知识。这使得经过训练的语言模型的输出生成基于事实的信息更加丰富。它使用屏蔽语言建模转换器进行培训,并学会从数百万个Wiki文档中检索参与。
